Climate does not affect the way you speak
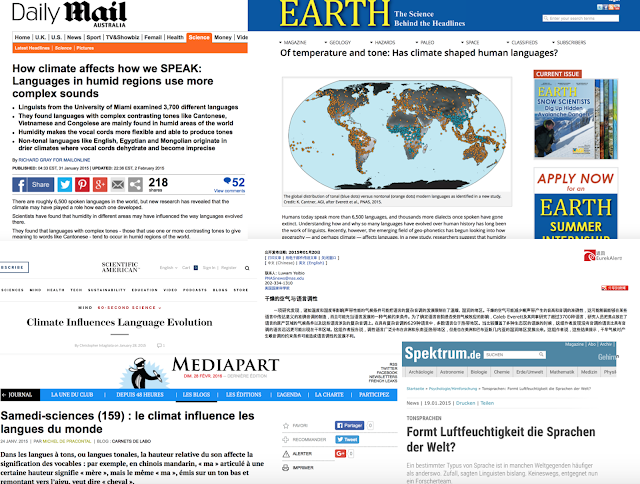
I was sipping a coffee in a café in Xishuangbanna, southwest China last January when I saw the following news item doing the rounds on the internet: This was a paper by Caleb Everett and two of my colleagues/arch-nemeses, Damián Blasi and Seán Roberts. Their claim in the paper is that climate can affect languages, in particular that tonal languages are easier to speak in humid climates. Tonal languages such as Chinese use pitch to make distinctions between words, for example xióngmāo means ‘panda’ (熊猫) while xiōngmáo means ‘chest hair’ (胸毛). Tonal languages tend to be found in warm and humid places around the equator such as Asia, Africa and Mexico. I had heard other people joke about this peculiar geographical pattern before, so I found it both amusing and surprising that someone had proposed the following half-way plausible explanation. When breathing in dry air, the larynx can become desiccated and people have less precise control over phonation. Tonal la

